
SAP HANA Development - SAP HANA Anonymous SQLScript Block
SAP HANA Development - SAP HANA Anonymous SQLScript Block.
Introduction
One of my tasks, in a recent project I was involved in, was to automate the creation of outbound delivery together with picking of goods and post goods issue. For that purpose, I used SAP Java Connector and SAP HANA JDBC Driver.
In this blog post, it is not my intention to discuss the code itself (as usual, it consists of successive calling of appropriate SAP BAPI's). Rather, I wish to point out the two choices I have made which, in my belief, can serve as good practice if you are looking for a simple, elegant solution to a complex issue.

The 2 choices I made are:
1. Using SQLScript to express business logic
Advantages
- avoids massive data copies to the application server and leveraging sophisticated parallel execution strategies of the database;
- reduces complexity of SQL Statements by breaking up a complex SQL statement into many simpler ones.
2. Using the same anonymous SQLScript block in all HANA landscape systems
An anonymous block is an executable DML statement which can contain imperative or declarative statements and is defined and executed in a single step.
All SQLScript statements, supported in procedures, are also supported in anonymous blocks.
Advantages:
- you can pass an anonymous block as a string parameter in the JDBC executeQuery method.
- there is no need for transporting stored procedures across the HANA system landscape (DEV --> TEST --> PRD).
The screenshot below shows an example of fetching all sales order items that can be delivered to a customer:
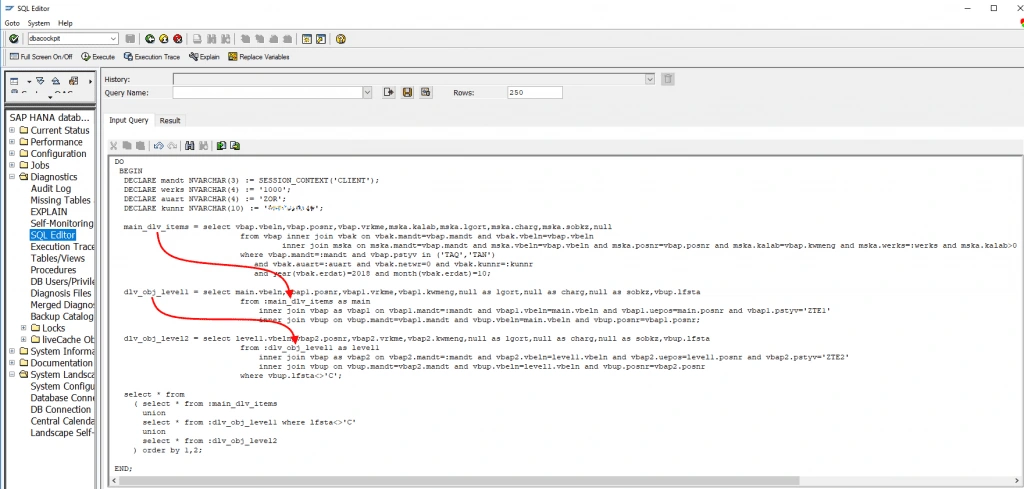
The local table variable main_dlv_items is bound to the select statement which returns sales order items on sales stock filtered for one particular sales order type and customer. The filtering is essential for reducing the amount of data as early as possible, especially before the Join operations.
The local table variable dlv_obj_level1 is bound to SQL, which consumes table variable main_dlv_items in the FROM clause by joining it with subquery for level 1 items. In the same manner, the local table variable dlv_obj_level2 is bound to SQL, which consumes table variable dlv_obj_level1 in the FROM clause by joining it with subquery for level 2 items.
In the end, the union of all three mentioned table variables is returned.
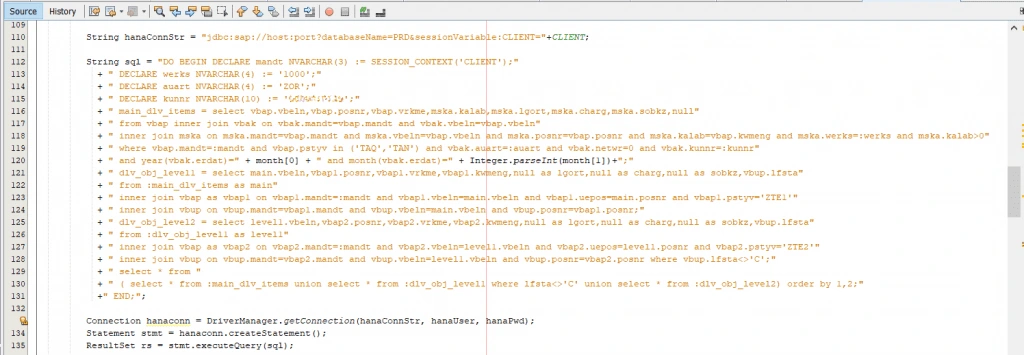
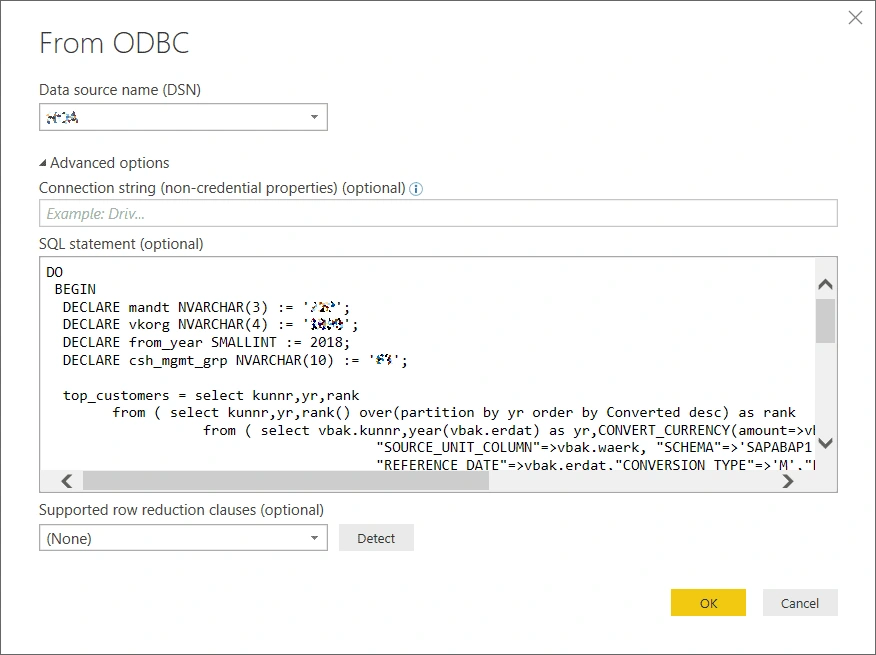
To keep an anonymous SQLScript block identical in all HANA landscape systems, I use the sessionVariable: connection option in the JDBC connection string. Session variables are defined in key-value pairs, and I use the CLIENT key to pass the client value:
String hanaConnStr = “ jdbc:sap://host:port?databaseName=PRD&sessionVariable:CLIENT= ”+CLIENT;
In the SQLScript, I can read the value by using the SESSION_CONTEXT function with 'CLIENT' as an argument. When you execute your anonymous SQLScript block in the DBACOCKPIT transaction, the client session variable is passed implicitly.
The changes are tracked in one place - the Java IDE with integrated support for Git, Mercurial, Subversion, CVS or ClearCase repositories.
This screenshot shows a code excerpt which relates to the described solution:
Epilogue
It may be worth comparing this solution to the initial SQL based solution which I also tried using for the same purpose:

Obviously, the SQL is less readable and, on top of that, it unnecessarily executes marked joins three times, which is both time consuming and resource intensive.
Appendix
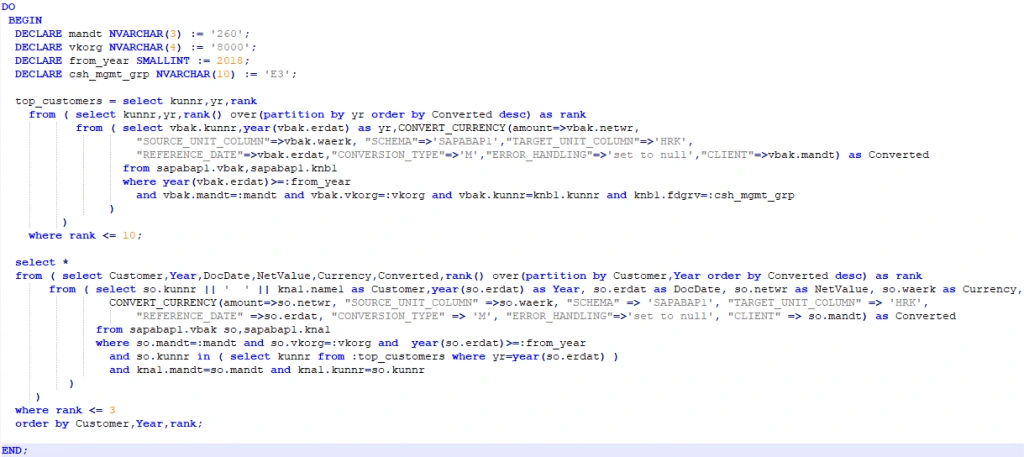
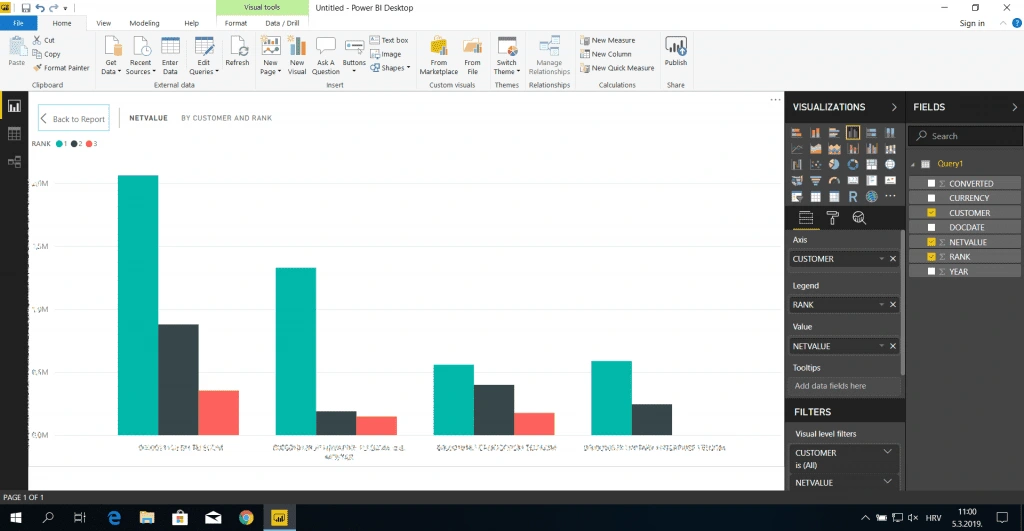
Another example uses an anonymous SAPScript block for creating reports in Microsoft Power BI Desktop. The customers and vendors in cash management and liquidity forecast are assigned to a planning group that reflects certain characteristics, behaviours and risks of the customer or vendor group. This enables you to categorise incoming and outgoing payments based on the amount, the type of business relation, or the probability of the cash inflow or outflow.
Our sales report returns the three greatest sales orders by net value for top ten customers in a particular planning group:
Summary
In SAP, most of the business logic is implemented in the application layer.
This architecture has two major drawbacks:
-
algorithms implemented in ABAP/Java do not automatically scale with the amount of data that needs to be analysed
-
data transfer time is growing with the amount of data that needs to be transferred from the database into the application layer.
The data-intensive application logic should stay at database level as much as possible. We can achieve this goal by using SAP HANA SQLScript, which is designed to provide superior optimisation by using massive parallelisation on multi-core CPUs.
By using an anonymous SQLScript block, we can combine the power of SQLScript with "good old" ABAP/Java imperative development paradigm.
I hope you have enjoyed this quick look into SAP HANA Development. Stay tuned to Eursap's SAP Blog,where we will be looking into other interesting SAP HANA Development in the coming weeks.
Author: Tomislav Milinovic
More Blogs


