
Eursap's SAP Tips: SAP HANA database storage methodology
Eursap's SAP Tips: SAP HANA database storage methodology.
We all know that the HANA database allows for rapid retrieval of data and compressed storage capacity, but how does it achieve this?
One of the key differences between a HANA database and traditional databases is the way the database tables are stored. Traditional databases use row storage for data tables, whereas HANA can use either row storage or column storage.
How does a column store work?
As an example, let’s view a table with the following entries.

Storing this table in a row store would like this:
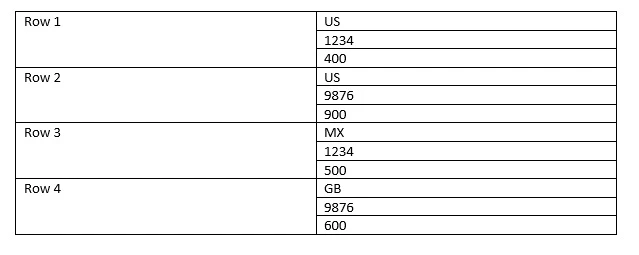
However, let’s now reorganise this into a column store. Now the storage looks like this:
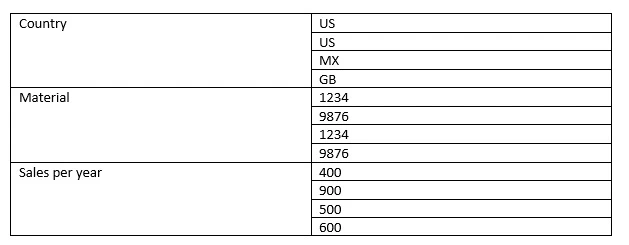
The difference here is that there are only three entries in the column store, whereas there are four in the row store. Furthermore, the column store contains repeated adjacent entries, for which the HANA database can employ highly efficient compression methods.
How does this work in practice?
Imagine that you are designing a report to show total sales per year. In the row storage method, your report would need to read every single row in the database to return the results. However, in the column store, it need only read one entry – the “sales per year”. Extrapolate this out to hundreds, thousands or even millions of records, and there is a big difference.
One additional advantage of column storage is that there is no need for index structures; as you can see from the example above, the index is built into the storage, unlike the row storage.
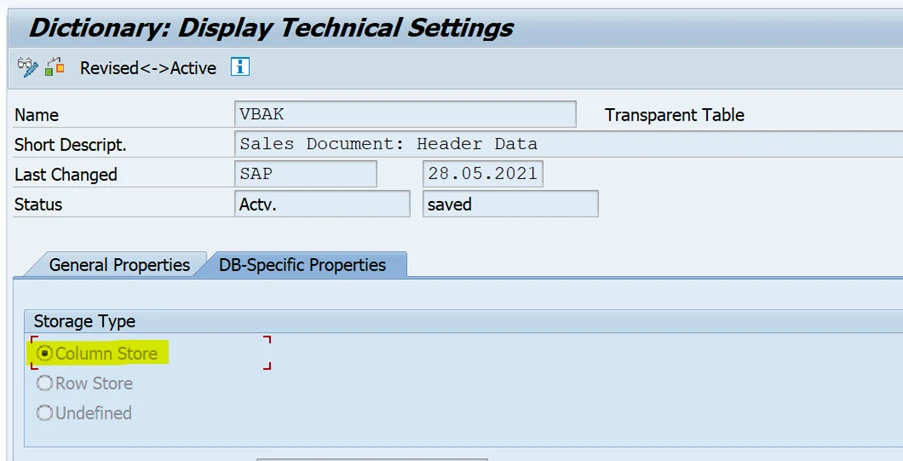
How do I know if a database table in SAP is a column store?
You can check the storage method by looking at the technical settings for a database table in transaction SE11.
More Blogs


