
Database Innovations in SAP HANA
Database Innovations in SAP HANA.
Introduction
SAP HANA technology makes reference to “rationalized” data structures. As well as “eliminating redundant fields” and “using any attribute as an index within tables.”
Today’s article will examine in some greater detail exactly what these database table handling and structural enhancements mean for the SAP user. After all, it is this technology that lies at the heart of the new S/4HANA system. At the same time, it is essential to distinguish between the terms “HANA technology” and “S/4HANA,” as they are not the same thing. The former is a set of technological enhancements, the latter the new upgrade to R/3 ECC software application or system.
This article is directed to business users who desire greater background on database table handling and to deliver some insight as to why this is large news for anyone working in and around big data.

 1. Columnar Database
1. Columnar Database
The first point is to explain the inherent advantage of the new columnar orientation of the HANA database table as compared to traditional ones organized in the more familiar rows of records.
It’s easiest to see this with some clear examples.
Consider, for example, the following “EMPLOYEE” database table consisting of four records organized in rows:
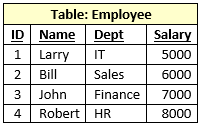
A simple table consisting of four records, broken down into three data fields each (not including the record number or ID).
In a row oriented database, that data is stored like this:
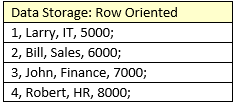
But in a column oriented database, the data is stored as follows:
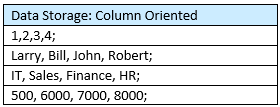
This may strike readers as appearing like transposed data in an MS Excel spreadsheet. They would be correct.
The columnar database offers a faster way to aggregate – or add up values. Suppose you want to run a common database query to answer the question, “How much are we paying the employees?”
In a row based database, all four records must be read to compute the sum as follows:
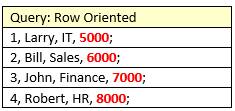
In a columnar database, only one read is necessary!
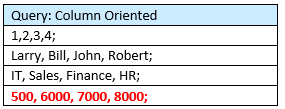
As illustrated in this example of a database comprising four records, the improved efficiency and performance of the faster aggregation will not be noticeable. But in a database with billions of records, the impact should be very clear. The improved read will be blazingly fast!
So query completion will be greatly enhanced – otherwise known as output data. But what about input? In this case, it’s the row-oriented database that will be faster since the new record inserts as a new row in one fell swoop. Consider the following input example in the two systems, adding new employee Clint:
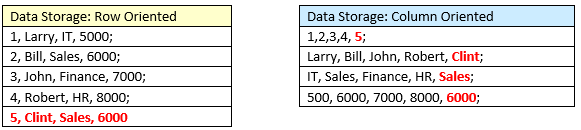
The columnar database will need to update four separate rows, which is more time-consuming. However data input or write speed is not typically an issue in data management. It’s the output, or the read speed when running queries that matters! Data is assembled for the purpose of retrieval. I am sure that most readers here will agree that a lot of time is wasted watching spinners on screens while your custom query is ripping through 4,000,000 rows of data.
2. All attributes as indexes
What is meant by the expression to “use any attribute as an index within tables?” This is where it gets really interesting. Suppose you have the above table of employees except, instead of four records, you have 200,000. Let’s add a new fourth field “Gender,” where the possible values are “M” or “F.”
In a row-oriented database, the gender attribute “F,” for example, is stored redundantly roughly 100,001 times. That’s a lot of dead weight in terms of storage. Running a query to pull all records where gender is F means that 200,000 rows must be interrogated for value “F” in the gender field. This is extremely inefficient, to say the least.
In a columnar database, you can simply go to column E and select for all records where the value is “F.”
It’s as if the database – in columnar form – is pre-selected for the convenience of running queries! By design, it’s much more efficient for fetching data. And this is where most time is consumed around Big Data. The time and efficiency savings are very real.
On top of this, add some proprietary data compression where table and data size is reduced by a factor of five. This means that data hosting costs can be minimized. And because of the smaller size, the whole database can be kept in memory instead of disk storage. Thus the efficiencies and retrieval speed improvements compound.
This is what is meant when SAP uses expressions like “Going Digital,” or “Real-Time Enterprise.” This kind of data organization, processing, and compression allows for running complex simulations on an immediate basis as opposed to overnight. Imagine cost allocation and payroll simulations, legendary for reading massive amounts of records, flying along with nearly immediate results – as opposed to watching a spinner on your screen.
These are but two examples of the innovations inherent within HANA technology which form the technical basis for SAP’s new S/4HANA application to replace yesterday’s R/3 ECC.
Author: James Olcott, SAP SD Lead Consultant (with thanks to Shyam Jajodia of LSI Consulting and Shyam Reganti of 3Core Systems, for their time and assistance)
More Blogs


